程序设计#3 - 结构体和数据结构入门
摘要:本篇教程将会详细讲述 Go 结构体的使用方法,并且搭配上经典数据结构栈(stack)来帮助理解。与往期教程相同的是,这次依然会使用线上题库的公开题。建议读者在学习结构体之后自己动手试一试,并且在函数部分体会一下使用值传参、指针传参以及引用传参的差异。这里的“传参”意思是把数据或变量传递给函数或方法进行处理的过程。 这种说法太抽象,不利于理解,请接着往下读。
此外,在额外部分会解释一些关于计算机架构的问题,例如指针的空间占用为什么会是 4 字节或 8 字节。
论结构体的诞生
我们在之前的教程中用的都是整数、小数、字符串还有数组等等这样平凡的数据类型。但是如果需要操作的东西越来越多,数据类型也大相径庭,我们之前采用的数据类型就不够看了。当数据类型逐渐复杂,只能存一种数据类型的数组显然不够用。为了解决这种尴尬的局面,我们需要一个新数据类型:结构体。
💡结构体的定义方式是这样。
type StructureName struct {
field1 type1
field2 type2
// 例如这样
/*
Name string
*/
/* 以此类推 */
}从定义方式我们就能看出来,结构体将不同的数据类型“缝合”(专业术语叫做“封装”)起来,成为一个数据构成的集合。它将多个不同类型、但逻辑上相关的数据捆绑在一起,形成一个更有意义的整体。
例如假设现在我们是一个网站的管理员,需要记录一名用户的身份信息。
如果我们仍然用多个变量来存的话,这对管理来说就是一场灾难。数组只能存相同类型的数据,所以把一名用户的全部信息存到一个数组里显然不现实。
如果真的要用不同的变量存同一用户的不同信息,实际文件中的代码会像这样。
// 包名,引入包
func main() {
userMyUsername := "aaaa"
userMyID := 12345
userMyEmail := "[email protected]"
userMyPassword := "abcdefg"
userMyVerified := false
/* 如此循环往复 */
}可以看到,仅仅是五条最基本的信息就要五个变量来存。如果像大论坛一样,动辄几十万人,那就要上百万条变量。
每次都这样想一个新变量名太让人头疼了。我们希望有一种新的数据类型,能够存放我们需要的全部用户数据。这种新数据类型叫做结构体。
💡如果使用结构体,代码可以这样写。
package main
import "fmt"
type User struct { // 定义用来记录用户基本信息的结构体
Username string
Id int
Email string
Password string
Verified bool
}我们以 Karlbaey 的妹妹 Karlbaeu 来举个例子,我们可以把她在论坛中的基本信息用结构体 User 来存放,这样就避免了多次定义变量,也让代码整齐有序。
func main() {
var Karlbaeu = User{
Username: "Karlbaeu",
Id: 1024,
Email: "[email protected]",
Password: "abcd1234",
Verified: true}
fmt.Printf(
"Karlbaeu 的用户名是:%s\n"+ // 注意是 + 连接符
"Karlbaeu 的用户 ID 是:%d\n"+
"Karlbaeu 的注册邮箱是:%s\n"+
"Karlbaeu 的密码是:%s\n"+
"Karlbaeu 是否是已验证用户?%t\n",
Karlbaeu.Username, Karlbaeu.Id, Karlbaeu.Email, Karlbaeu.Password, Karlbaeu.Verified,
)
}输出
Karlbaeu 的用户名是:Karlbaeu
Karlbaeu 的用户 ID 是:1024
Karlbaeu 的注册邮箱是:[email protected]
Karlbaeu 的密码是:abcd1234
Karlbaeu 是否是已验证用户?true如果需要修改某个特定的元素也很简单。例如,Karlbaeu 换邮箱了,现在把她的邮箱换成正活跃的邮箱。
要修改特定元素可以使用 Structure.Field = xxx 这样的语法。例如,在上面主函数的下方加两行新代码。
Karlbaeu.Email = "[email protected]"
fmt.Printf("Karlbaeu 的新邮箱是:%s\n", Karlbaeu.Email)新增输出
Karlbaeu 的新邮箱是:[email protected]当然也可以将整个结构体初始化为零值。一个结构体初始化为零值,就等于它包含的所有数据都被设置为默认值,例如 bool 类型将被设置为 false。
func main() {
var Karlbaeu User
// 也可以使用
// Karlbaeu := new(User)
fmt.Println("Karlbaeu 的基本信息:", Karlbaeu)
}使用 var Karlbaeu User 初始化的是一个值,Karlbaeu := new(User) 初始化的是一个指针。
输出
Karlbaeu 的基本信息: { 0 false}需要注意,定义好的结构体不能直接用,必须使用 var 或者 := 来将结构体实例化(instantiate)。打个比方,结构体是一台汽车的设计蓝图,蓝图当然不能给人开,所以需要照着蓝图造一台车,已经造好的车才是能给人开的,这里的车就是实例(instance)。这个依照蓝图造车的过程就叫做实例化。实例化是面向对象程序设计的内容,在支线面向对象程序设计1中再继续研究,这里只需要知道为什么这样做就行。
package main
import "fmt"
type Car struct {
Volume int // 单位是 L
Weight int // 单位 kg
Color string
}
func main() {
myCar := Car{Volume: 2574, Weight: 1200, Color: "White"}
fmt.Printf("我的车的体积:%d L\n", myCar.Volume)
fmt.Printf("我的车的质量:%d kg\n", myCar.Weight)
fmt.Printf("我的车的颜色:%s\n", myCar.Color)
}输出
我的车的体积:2574 L
我的车的质量:1200 kg
我的车的颜色:White⚠注意:如果不将 Car 实例化,直接输出 Car,就会编译错误。
# command-line-arguments
.\main.go:12:33: Car (type) is not an expression意思是,Car 是一个类型而不是表达式。此时 Car 与 int、string 等类型是同一层级的。
结构体的方法和函数
定义了结构体之后,如果只是用它来存数据显然是不够用的。我们需要写几个与结构体有关的函数,这样结构体就有自己的行为了。函数的定义方式在上一篇教程就有提到,但是在这里,方法是与特定类型关联的函数,通过接收者(receiver)绑定到类型上,因此这里不再称作函数(function),而是称作方法。
→程序设计#2 - 序列入门和缓冲输入输出 - 💡如何写一个函数 | Karlblogs
例如在这里定义一个矩形。我们知道,只要确定了一个矩形的宽和高,这个矩形的面积就确定下来了。
那么可以实现一个计算矩形面积的方法,这个方法完全依赖于矩形这个结构体。
package main
import "fmt"
type Rectangle struct {
Width int
Height int
}
func (r Rectangle) Area() int {
return r.Height * r.Width
}
func main() {
var rect = Rectangle{Width: 10, Height: 20}
fmt.Println(rect.Area())
}在 func (r Rectangle) Area() int 这一行代码中
func是定义函数的关键字,在这里用来定义方法。(r Rectangle)的意思是,把这个方法作为结构体Rectangle的方法。r表示参数名,它的类型就是Rectangle。Area()是方法名,可在程序的其他地方用InstanceRectangle.Area()调用这个方法。int表示返回值的类型。
⚠这里,Area() 是结构体 Rectangle 的方法。
方法也可以用指针传入,这样能够节省内存。
如果我们把 Area() 改写成一个输入参数是 Rectangle 的函数,就会像这样。
func Area(r Rectangle) int {
return r.Height * r.Width
}结构体如果首字母大写,就说明这个结构体是可导出的,意思是你可以在这个程序外使用这个结构体。如果首字母小写,就不能在程序外使用或者修改结构体。结构体里的字段(例如上文 Rectangle 的 Width 和 Height)、结构体的方法(例如 Rectangle.Area())、程序内写好的函数以及用 const 关键字定义的常量,都是这样。
函数的三种传参
首先我们需要知道函数传参是怎么一回事。它就是字面意思,把参数传递给函数。但是函数传参的方式很多。
首先,Go 语言的函数只有一种参数传递:值传递2(pass by value)。
意思就是说,当我们把变量或指针作为参数传递给函数的时候,其实是把参数复制了一份,再让函数进行操作。
也就是说,像 C++ 的三种传参(值、指针和引用),在 Go 里面统统没有。因为:
- 如果是传入基本类型(
int以及string等),函数会复制一份实际数据。 - 如果是传入引用类型(例如之前说过的切片),函数会复制一份这个引用类型的内存地址。
- 如果是传入指针,函数会复制一个指针,而不是这个指针指向的数据。
我们也可以把这一篇教程所说的结构体作为参数传递给函数。
但是,如果结构体非常大,已经占用了好几个兆字节,那么不建议把结构体作为值,而应该创建一个指向结构体实例的指针,直接操作指针就行。这能够大大减少程序运行时占用的内存,因为一个指针通常只有 4 字节或 8 字节,原因在后面解释,远远比一个大型结构体实例占用的内存少。不要忘了,如果向函数传入结构体,那就相当于复制了一个与原来一样大的结构体。
虽然从技术层面(当前我们离这个层面特别特别远)来说,函数只有值传参。但我们完全可以通过操作值,使它们产生与引用传参和指针传参相同的效果。
上一句话比较拗口,具体的例子请看下面。
值传参
这种传参适用于值比较小,而且不需要修改值本身的函数。
比如,我们希望实现一个函数,让它能够运算输出两个整数的和。
非常简单,代码实现像这样。
func AddInt(x, y int) int {
return x + y
}
func main() {
x := 2
y := 3
fmt.Printf("x + y == %d\n", AddInt(x, y))
}输出
x + y == 5在这个过程里,主函数中的 x 和 y 都没有被改变,AddInt() 只是复制了一份 x 和 y 的副本给函数进行计算。
值传参是最安全的,在函数内对值的任何修改都不会影响到函数外。
指针传参
指针传参一定要优先检查空指针。 如果操作空指针就会导致 panic。
package main
import "fmt"
func NilInt(a *int) { // 测试空指针
*a = 10 // 给空指针赋值,会导致 panic
fmt.Println(a)
}
func main() {
var a *int // 空指针
NilInt(a)
}输出
panic: runtime error: invalid memory address or nil pointer dereference
[signal 0xc0000005 code=0x1 addr=0x0 pc=0x5aa90e]
goroutine 1 [running]:
main.NilInt(0xc0000021c0?)
E:/DRAFTBOX/Go/main.go:6 +0xe
main.main()
E:/DRAFTBOX/Go/main.go:12 +0x15解决办法就是在函数开头加一个判断空指针的逻辑。
func NilInt(a *int) {
if a == nil { // 判断空指针
fmt.Println("a is a nil pointer.")
return
}
*a = 10
fmt.Println(a)
}输出
a is a nil pointer.因为下面涉及的指针传参都不是空指针,所以判断空指针的逻辑都会省略。
如果我们需要把两个数 a 和 b 的值调换一下,需要经过三步操作。
- 将
a的值赋给临时变量temp(temporary variable,临时变量的头四个字母)。这是用temp暂存a的值。 - 将
b的值赋给a。 - 将
temp的值赋给b。
如果我们仍然用上一节值传参的方法,会导致什么都没有发生。
func SwapInt(a, b int) { // 我们不需要输出值,因为整个函数都不涉及 a 和 b 以外的值
temp := a
a = b
b = temp
}
func main() {
a := 2
b := 3
SwapInt(a, b)
fmt.Printf("a == %d\nb == %d\n", a, b) // 预期:a == 3 b == 2
}输出
a == 2
b == 3出现这种情况的原因是 SwapInt() 操作的是副本,而不是我们在主函数里定义好的 a 和 b。
解决这个问题的办法就是使用指针,把内存地址对应的数字交换即可。
func SwapInt(a, b *int) {
temp := *a // 把 a(内存地址)对应的值赋给 temp
*a = *b // 把 b 对应的值赋给 a 对应的值
*b = temp // 把 temp 的值赋给 b 对应的值
}
func main() {
a := 2
b := 3
SwapInt(&a, &b)
fmt.Printf("a == %d\nb == %d", a, b) // 正确输出
}输出
a == 3
b == 2我们把 SwapInt() 函数改为传入指针。这时候,我们复制的就是指针的副本了。
这时候 a 的指针 &a 记录了 a 的值,暂时先把这个值记录给 temp。
然后继续照着我们开始的步骤,到最后 &a 指向的是 b 的值,&b 指向的是 a 的值。这就是我们想要的。
所以即使在 SwapInt() 执行结束,销毁了临时的指针副本后,我们依然成功交换了 a 和 b 的值。
我们可以打个比方。
现在 Karlbaeu 穿着一件夹克衫,左右边口袋分别放着一张 10 元钞票和一张 20 元钞票。现在 Karlbaeu 想要把左右边口袋里的钞票交换一下,但是她的每个夹克口袋最多只能放一张钞票。
Karlbaeu 首先试试把两张钞票复印了一份3,然后按照上面所说的步骤交换了两张钞票的复印件。但是这些复印件很神奇,在交换完之后会自动销毁。Karlbaeu 只能把两张钞票放回原位。
这就是我们运用值传递的弊端,我们操作的始终是一份副本(也就是上面说的“复印件”),而且副本操作完后还会自动销毁。真正的值从来没有变过。
Karlbaeu 发现这样既麻烦又没用,所以她想了一个好方法,就是把两个口袋的钞票的位置分别用一张小纸条记录下来。她写了两张纸条:“左口袋里的是 10 元”,“右口袋里的是 20 元”(也就是上面输入的两个指针 &a 和 &b)。
现在 Karlbaeu 按照第一张纸条找到了 10 元钞票,把它暂时地放在桌面上(存放在临时变量里),然后把 20 元钞票放进已经清空的左口袋,最后把桌面上的 10 元钞票放进右口袋。
这样就完成了交换的全过程。两条记录钞票位置的纸条在操作完后自动销毁了,但我们不关心这些,因为钞票确实完成了交换。
这样传参能成功的原因是,即使我们操作的是指针的副本,指针对应的值也是不会变的,而我们的目的是操作指针对应的值,所以借助指针完成这个操作即可。
其实要交换值还有一种更简洁的写法。
a, b = b, a指针传参还有一种用法,就是用在大型结构体的时候。
package main
import "fmt"
type Rectangle struct {
Width int
Height int
}
func SwapSides(r *Rectangle) { // 交换矩形的宽和高
temp := r.Width // 自动解引用
r.Width = r.Height
r.Height = temp
}
func main() {
var rect = Rectangle{Width: 10, Height: 20} // 宽 10 高 20
fmt.Printf("宽:%d\n高:%d\n", rect.Width, rect.Height)
SwapSides(&rect)
fmt.Printf("宽:%d\n高:%d\n", rect.Width, rect.Height)
}输出
宽:10
高:20
宽:20
高:10它确实地交换了矩形的宽和高,原理之前已经说过了。指针传参也像前文所说能够节省内存。
但是我们看一看 SwapSides() 这个函数,它输入的是一个指向矩形结构体实例的指针,但是在处理中我们没有用 (*r).Width 来解引用。
这是因为 Go 非常聪明,当我们访问结构体指针的字段时,它会自动解引用。换句话说,SwapSides() 也可以用这种写法。
func SwapSides(r *Rectangle) {
temp := (*r).Width
(*r).Width = (*r).Height
(*r).Height = temp
}它们是完全等价的。
引用类型传参
我们以传递切片(切片是引用类型)为例。
事实上我们已经在之前的 程序设计#2 - 序列入门和缓冲输入输出 | Karlblogs LeetCode 344 中接触了引用传参。
我们写一个主函数试着调用这个它,并且我们把原题中的 []byte 改为 []int。
func ReverseSlice(s []int) {
l := 0
r := len(s) - 1
for l < r {
s[l], s[r] = s[r], s[l] // a, b = b, a 表示交换 a 和 b 的值
l++
r--
}
}主函数这样写。
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7}
ReverseSlice(a)
fmt.Println(a)
}输出
[7 6 5 4 3 2 1]按照 Go 的值传递,传递切片进入函数时,应该复制一份新切片才对。这样的话操作不会影响到原来的切片。但它确实把原切片给修改了。
原因是,**即使函数复制了一份原切片,原切片和函数内切片的副本仍然是共享底层数组的。**这意味着即使函数内外的数据不同,它们的底层也是一样的。
切片复制时,实际上是复制一份切片头。
切片头包括三个要素:指针(Ptr)、长度(Len)和容量(Cap)。
- 指针指向切片的头元素。
- 长度表示当前切片中的元素数量。
- 容量表示当前切片最多容纳元素的数量。
其中容量可以使用函数 cap() 来获取。通常来说,一个切片的容量就等于切片长度。
package main
import "fmt"
func main() {
a := []int{1, 2, 3, 4, 5, 6, 7}
fmt.Println(cap(a))
}输出
7我们也可以用 make() 函数来自定义切片的容量。
package main
import "fmt"
func main() {
a := make([]int, 7, 10)
fmt.Println(cap(a))
fmt.Println(a)
}输出
10
[0 0 0 0 0 0 0]如果是从数组里截取出的切片,那切片的容量就是从截取的头到原数组的尾。
package main
import "fmt"
func main() {
b := [8]int{9, 8, 7, 6, 5, 4, 3, 2}
c := b[4:6]
fmt.Printf("c 的值:%v\n", c)
fmt.Printf("c 的容量:%d\n", cap(c))
}输出
c 的值:[5 4]
c 的容量:4切片 c 的长度是 2,但是容量是 4。这是因为 c 实际容量是通过数组长度减去起始索引得来的,在上面的代码中就是 len(b) - 4 == cap(c)。
引用传参可能会因为 append() 触发超出容量。
package main
import "fmt"
func ModSlice(t []int) {
t[0] = 6512345
}
func main() {
b := []int{1, 3, 5, 7}
ModSlice(b)
fmt.Printf("b 的值是:%v", b)
}输出
b 的值是:[6512345 3 5 7]现在没问题,但是我们在 ModSlice() 中加入一个 append() 函数,结果就会不同。
修改函数
func ModSlice(t []int) {
t[0] = 6512345
t = append(t, 123333)
t[2] = 101010
fmt.Printf("函数内的 t:%v\n", t)
}输出
函数内的 t:[6512345 3 101010 7 123333]
b 的值是:[6512345 3 5 7]这是因为原先 b 的容量只有 4,无法继续往后添加元素。如果需要添加元素,就必须分配一个新的切片。这体现在 ModSlice() 中,就是扩容切片,然后后续的操作都发生在这个新切片中。
这种操作无法应用到原切片上的现象,我们称作失联。
解决失联的方法有两种。
第一种是,在创建切片时就把容量设置得足够大,然后用指针传参。
package main
import "fmt"
func ModSlice(t *[]int) {
*t = append(*t, 10)
}
func main() {
a := make([]int, 0, 10)
ModSlice(&a)
fmt.Println(a)
}但是要强调,足够大的容量不是必须的,但是这样可以防止反复扩容,优化性能。
第二种是,给函数设置一个返回值,这种操作非常直接,不多解释。
package main
import "fmt"
func ModSlice(t []int) []int {
t = append(t, 10)
return t
}
func main() {
a := make([]int, 0, 10)
a = ModSlice(a)
fmt.Println(a)
上面两种方法的输出
[10]数据结构 - 栈
💡栈(Stack)是一种后进先出(LIFO,Last In First Out)的数据结构。
距离栈的入口最近的元素,我们叫做栈顶元素。相应的,距离栈的入口最远的元素叫做栈底元素。
我们画图解释这个过程。

我们可以通过结构体来实现这一个数据结构。
因为栈可能非常非常大,所以我们调用方法时都会使用指针来节约内存。
我们以这个模板 B3614 【模板】栈 - 洛谷 作为辅助。默认栈里面所有的元素都是整数。
先导入必要包。
package main
import (
"errors" // 错误包,用来处理空栈
"fmt"
)然后因为栈中的元素都是整数,所以我们直接用一个切片就行。
type Stack struct {
elements []int
}当我们初始化一个栈时,通常调用 NewStack() 函数,它返回一个新栈的内存地址。以后我们初始化一个结构体时,全部使用 NewXxx() 这种格式的函数
func NewStack() *Stack {
return &Stack{
elements: make([]int, 0),
}
}现在我们需要实现栈的四个方法:Push()(将元素压入栈)、Pop() (将栈顶元素弹出栈)、Query()(也叫 Peek(),查看栈顶的元素)以及 Size()(输出栈的元素个数)。
先从 Push() 开始。我们使用 append() 函数实现。
func (st *Stack) Push(elm int) {
st.elements = append(st.elements, elm)
}然后是弹出元素 Pop()。因为栈有可能是空的,所以我们应该先检查栈不是空的,再弹出。
func (st *Stack) Pop() error { // 不考虑弹出的元素究竟是什么
if len(st.elements) == 0 {
return errors.New("Empty")
}
st.elements = st.elements[:len(st.elements)-1] // 使用切片弹出元素
return nil
}接着,实现 Query() 方法时,一样要先检查空栈。
func (st *Stack) Query() (int, error) {
if len(st.elements) == 0 {
return 0, errors.New("Anguei!") // 栈里没有元素,默认返回 0,错误类型返回 Anguei!
}
return st.elements[len(st.elements)-1], nil
}Size() 方法只要简单地输出栈长度就可以了。
func (s *Stack) Size() int {
return len(s.elements)
}到这里的话其实我们就可以着手写主函数了。但是考虑到有时候我们需要输出栈的全部元素,这时候我们需要使用 fmt 包的接口(interface,使用方法往下翻)Stringer() 来输出一个栈。
源码中的 Stringer() 是这样定义的。
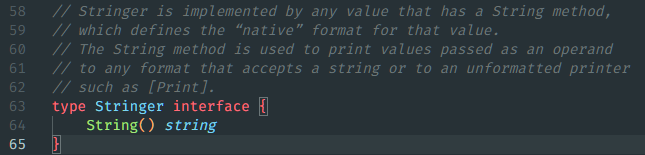
我们将从栈底到栈顶依次输出。例如 1 -> 2 -> 3,箭头的末尾就是栈顶元素。
func (st *Stack) String() string { // 不需要显式声明,只要有 String() string 就算实现了 Stringer 接口
if len(st.elements) == 0 {
return "Empty"
}
var res string
for i, elm := range st.elements {
if i > 0 {
res += " -> "
}
res += fmt.Sprintf("%d", elm)
}
return res
}这样的话,当我们调用 fmt.Println() 输出这个栈时,程序就会按照我们设置的规则输出。
在洛谷提交时我们用不到输出栈,所以这段代码是可选的。
栈的优化
现在我们开始写主函数。这里涉及高速读写,可前往 程序设计#2 - 序列入门和缓冲输入输出 - 高速读写 | Karlblogs 阅读。
首先我们需要知道,这一道题用的是标准输入输出而不是核心代码,所以我们需要一种方法加速读写。
因为 push 后有空格以及一个数字,我们使用 bufio.NewScanner() 结合上 scanner.Split(bufio.ScanWords) 会比单纯使用自定义解析效率更高。因为 bufio 写的东西大多都已经压进了底层代码,这比我们手动写一个更快。
注意:因为原题中的 x 范围在 [0, 264),我们需要把原来栈中的 int 类型改为 uint644,否则就会 panic。
考虑到每次扩容切片都是一笔不小的时间空间开销,我们首先要限定栈最大的容量。最坏情况下栈里要容纳 n 个元素,设置为 n 即可。
标准输出 os.Stdout 不会自带换行,我们在每次输出后都要自己写一次换行。
全部代码如下。有一些以前没有见过的函数在注释里有用法。
package main
import (
"bufio"
"errors"
"os"
"strconv"
)
type Stack struct {
elements []uint64 // 统统用 uint64 防止 panic
}
func NewStack(cap int) *Stack { // 通常来说 n 就足够了
return &Stack{elements: make([]uint64, 0, cap)}
}
func (st *Stack) Push(elm uint64) {
st.elements = append(st.elements, elm)
}
func (st *Stack) Pop() error {
if len(st.elements) == 0 {
return errors.New("Empty")
}
st.elements = st.elements[:len(st.elements)-1]
return nil
}
func (st *Stack) Query() (uint64, error) {
if len(st.elements) == 0 {
return 0, errors.New("Anguei!")
}
return st.elements[len(st.elements)-1], nil
}
func (st *Stack) Size() int {
return len(st.elements)
}
func main() {
scanner := bufio.NewScanner(os.Stdin) // 不使用 Reader 而是 Scanner,这样可以加速
scanner.Split(bufio.ScanWords)
writer := bufio.NewWriter(os.Stdout)
defer writer.Flush()
scanner.Scan()
t, _ := strconv.Atoi(scanner.Text()) // Atoi 把字符串转换成整数
// 它有两个返回值,第二个是错误类型。因为我们能保证不会报错,所以销毁即可
scanner.Scan()
n, _ := strconv.Atoi(scanner.Text())
st := NewStack(n)
for range n {
scanner.Scan()
opr := scanner.Text()
switch opr {
case "push":
scanner.Scan()
x, _ := strconv.ParseUint(scanner.Text(), 10, 64) // 十进制,64 位整数
st.Push(x)
case "pop":
if err := st.Pop(); err != nil { // 先判断是否有错误
writer.WriteString("Empty\n")
}
case "query":
if elm, err := st.Query(); err != nil {
writer.WriteString("Anguei!\n")
} else {
writer.WriteString(strconv.FormatUint(elm, 10) + "\n") // 把 uint64 类型数字转换成 10 进制表示
}
case "size":
writer.WriteString(strconv.Itoa(st.Size()) + "\n") // Itoa 把整数转换成字符串
}
}
}
}这样的代码可以 AC,贴一张参考用时和占用内存。
如果我们使用上一篇教程的高速读写,第八个测试点会超时。
接口的使用方法
输出栈时我们运用了 fmt 包中的 Stringer 接口,它只有一个字段。
这意味着,我们让结构体实现了 String() 方法,这个方法的输出值类型是 string,就算实现了这个接口。
我们在 String() 方法中定义的输出方式会在 fmt 包中的输出函数自动调用。
比如我们定义一个新的结构体 Series,它就是一个数组。我们让它在输出时每两个元素之间夹一个连字符 -。
package main
import (
"fmt"
"strconv"
)
type Series []int
func (s Series) String() string { // 调用 Stringer 接口
var res string
for i, s_i := range s {
if i > 0 {
res += " - "
}
res += strconv.Itoa(s_i)
}
return res
}
func main() {
s := Series{1, 3, 5, 7, 9}
fmt.Println(s)
}输出
1 - 3 - 5 - 7 - 9Stringer 接口能决定一个结构体应该怎样用 fmt 包中的函数输出。
我们也可以自己写一个接口。接口通常以 er 或 or 结尾。
package main
import "fmt"
type Rectangle struct { // 矩形结构体
Height int
Width int
}
type RectCalculator interface { // 有关于矩形的接口
Area() int // 计算面积
Perimeter() int // 计算周长
}
func (r Rectangle) Area() int {
return r.Height * r.Width
}
func (r Rectangle) Perimeter() int {
return 2 * (r.Height + r.Width)
}
func RectInfo(r RectCalculator) { // 此时这个函数期望一个 RectCalculator 接口
// 我们可以直接输入 Rectangle 类型的数据
// 因为我们已经为 Rectangle 实现好了 RectCalculator 的两个方法
fmt.Printf("矩形的面积:%d\n矩形的周长:%d\n", r.Area(), r.Perimeter())
}
func main() {
var rect = Rectangle{Height: 60, Width: 50}
RectInfo(rect)
}输出
矩形的面积:3000
矩形的周长:220Go 的接口实现是隐式的,意思是,我不需要给 Rectangle 结构体声明,我使用了 RectCalculator 这个接口。只要实现好了直接调用就行。
当一个接口什么都没有的时候,这时候我们管它叫做空接口。空接口没有任何方法,所有类型都实现了空接口。它可以表示任何类型的值。
/* 代码块 */
type EmptyPrinter interface{}
// 也可以写
// type EmptyPrinter any
func Printa(v EmptyPrinter) {
fmt.Println(v)
}
func main() {
var rect = Rectangle{Height: 60, Width: 50}
Printa(rect)
}输出
{60 50}any 是空接口 interface{} 的别名。
我们可以使用类型断言(type assertion)来判断接口值的具体类型。
package main
import "fmt"
type Rectangle struct {
Height int
Width int
}
type Square struct {
Side int
}
type ShapeJudger interface{}
func Shape(v ShapeJudger) { // 开始类型断言
if rect, ok := v.(Rectangle); ok { // 如果 rect 是 Rectangle 类型的数据,ok 才是 true,接着向下执行
fmt.Printf("This is a Rectangle.\nWidth: %d\nHeight: %d\n", rect.Width, rect.Height)
} else if sq, ok := v.(Square); ok {
fmt.Printf("This is a Square.\nSide: %d\n", sq.Side)
} else {
fmt.Println("Unknown.")
}
}
func main() {
var rect = Rectangle{Height: 60, Width: 50}
var sq = Square{Side: 100}
a := 10
Shape(rect)
Shape(sq)
Shape(a)
}输出
This is a Rectangle.
Width: 50
Height: 60
This is a Square.
Side: 100
Unknown.额外部分
指针占用内存(以及 CPU 是怎么操作内存的)
下面的东西比较复杂,看不明白的话我再改。
首先,我们要明白,指针就是地址,地址就是指针。
一个指针,在 32 位机器上,占用 4 字节;在 64 位机器上,占用 8 字节。指针占用大小不是瞎说的,它跟中央处理器的运算方式有关。
这里的 xx 位表示中央处理器(CPU,Central Processing Unit,有时候简称处理器)通用寄存器5的宽度,也就是数据总线宽度。拿一台 32 位机器来说,它的中央处理器一次性能够操作 32 个二进制数,也就是 32 个比特。
处理器通常不直接与硬盘交互,而是借内存作为中转。所以就需要给内存地址编码,方便处理器处理数据。
处理器与内存交互的模式可以抽象成下面这张图。(实际数据和索引都用十六进制表示)

例如,我们想在内存中读一个数字 9,处理器是这样做的。
- 通过地址总线寻找 9 在内存中的位置。
- 通过控制总线决定操作是读还是写。
- 通过数据总线,把数字 9 传递给处理器。
从上面的过程中我们能总结出三点。
- 地址总线直接决定处理器寻找内存地址的能力。
- 控制总线直接决定处理器的操作内存的能力。
- 数据总线直接决定内存和处理器之间的数据传输速度。也可以说它决定处理器一次最多处理的数据量。
我们以 32 位机器为例,它的处理器一次能够操作 32 个比特,那我们一次读取的整数最大也是占用 32 个比特(4 个字节)。这是数据总线决定的。
指针本质上是一个整数,这个整数记录了一个内存地址,只不过它平时显示为十六进制(也就是 0x123456 这种格式的数字)。
因为机器一次性最多读 4 字节的数据,如果一个指针的空间占用超过了 4 字节,就会导致浪费。 32 位机器无法一次读取指针后寻找内存地址。
32 位机器的地址总线通常一次处理 32 个比特,每个比特的值要么是 1,要么是 0。也就是说,机器的内存索引最大值是 232-1(内存索引从 0 开始),也就是最大控制 4 GiB6的内存空间。7
所以只要一个指针的空间占用限制在 4 个字节,就能让处理器按照指针找到所有的内存地址,也就能读取到所有在内存中的值。
在 64 位机器上同理,8 个字节就能访问所有的内存地址。
所以这就是为什么指针占用的字节数是固定的。指针的空间占用只和机器位数有关。
另外,操作内存的最小单元是字节(byte)而不是比特(bit),这是计算机底层架构决定的。不过我们通常不会只操作一个字节,而是多个字节一起组成更大的块(例如缓存行)一起处理,这样可以提高效率。
💡总结一下
我们学到了结构体用法和结构体的实例化方式。并且我们接触了函数(方法)的三种传参。然后,我们借助结构体,实现了经典数据结构栈。额外部分里面涉及了指针大小和计算机架构(尽管讲得非常粗糙)。
下一篇不是主线 #4,而是暂时分开一条支线:#3-1 面向对象程序设计。
🎉撒花🎉
Footnotes
正在磨墨,会加急赶出来。面向对象程序设计是非常关键的概念,几乎所有编程语言都用得到。 ↩
严格地说,Go 所有类型都是值类型。我们管切片之类的东西叫做“引用类型”,是因为操作切片给人的印象就是在操作一个引用自其他数据的类型。这是非常专业的说法,我们一般用不到。它不影响我们下文对于三种传参的理解。 ↩
Karlbaeu 的钞票没有运用欧姆龙环防伪技术,她的打印机也不会拒绝复印有欧姆龙环的纸张。 ↩
uint64的意思是无符号 64 位整数(unsigned int64),它最小值是 0,最大值是 264-1。 ↩通用寄存器是中央处理器内部的一组高速存储单元,用于临时存放程序执行过程中的数据和指令。它们通常按功能分为多种类型,如数据寄存器、地址寄存器等,以提高计算和访问效率。它们的用途极其广泛,而且使用非常高频,因此得名通用寄存器。寄存器的位数(如8位、16位、32位或64位)会影响处理器单次能处理的数据量,进而影响程序执行效率,但不是唯一因素——处理器架构、指令集和内存速度等也会共同影响性能。现代计算机中,通用寄存器的位数通常与处理器的字长(也就是处理器的位数)一致(例如64位处理器配备64位寄存器)。 ↩
4GiB == 22 GiB == 212 MiB == 222 KiB == 232 字节 == 235 比特 ↩
有一些方法(比如 PAE 技术)可以让机器能访问的内存超过 4 GiB 的限制,但这里不讨论。 ↩